У самого значимого в мире поисковика «все ходы записаны» — информация, попавшая в поле зрения поисковых роботов Google, раз и навсегда сохраняется в виде сохранённой копии. Эта копия иногда очень нужна веб-журналистам — чтобы получить важные, но уже удалённые сведения. Но как получить к ним доступ? Как осуществлять поиск по кэшу Google?
Если вы ищете что-то через Google, то найти сохраненную копию можно и через обычный интерфейс поисковика. Нажмите на зелёный треугольничек справа от ссылки на сайт, затем — на надпись «Сохраненная копия». Нажмите на неё — и посмотрите резервную копию имеющейся информации, которая попала в цепкие лапы «гугла».
Поиск через адресную строку

Есть два способа:
Способ №1
Введите в адресную строку своего веб-браузера (Ghrome, Safari, Mozilla, Internet Explorer, Opera и т.д.) следующую информацию:
http://webcache.googleusercontent.com/search?q=cache:http://сайт Вместо сайт подставьте нужный вам сайт.
При желании можно посмотреть версию страницы без графики (только текст, своего рода режим Readability). Для этого достаточно нажать на «Текстовая версия» в правом верхнем углу экрана.

Способ №2
В браузере перед адресом страницы допишите слово «cache: ». В результате вместо самой страницы откроется её копия в кэше Google. Например:

Важно: Google в вашем браузере должен быть поиском по умолчанию. Если у вас не так — вводите «cache: » и адрес страницы в поисковой строке на google.com.
Вот и всё! Теперь вы можете искать в веб-кэше Google всё, что захотите — и когда захотите.
P.S. Хотите, чтобы запрос на кэш Google всегда был под рукой? Добавьте эту страницу в закладки. Как это сделать быстро и эффективно? Для Мас работает сочетание клавиш Cmd + D, для Windows — Ctrl + D.
Иногда, зайдя на (ранее существовавшую) страницу, мы получаем 404 ошибку — страница не найдена. Эта страница удалена, сайт не доступен и т. д., но как просмотреть удалённую страницу ? Попробую дать ответ на этот вопрос и предложить четыре готовых варианта решения этой задачи.
Вариант 1: автономный режим браузера
Для экономии трафика и увеличения скорости загрузки страниц, браузеры используют кэш. Что такое кэш? Кэш (от англ. cache ) — дисковое пространство на компьютере, выделенное под временное хранение файлов, к которым относятся и веб-страницы.
Так что попробуйте просмотреть удаленную страницу из кэша браузера. Для этого — перейдите в автономный режим .
Примечание : просмотр страниц в автономном режиме возможен, только если пользователь посещал страницу ранее и она ещё не удалена из кэша.
Как включить автономный режим работы браузера?
Для Google Chrome , Яндекс.Браузер и др., автономный режим доступен только как эксперимент. Включите его на странице: chrome://flags/ — найдите там «Автономный режим кеша» и кликните ссылку «Включить ».
 Включение и выключение автономного режима в браузере Google Chrome
Включение и выключение автономного режима в браузере Google Chrome
В Firefox (29 и старше) откройте меню (кнопка с тремя полосками) и кликнуть пункт «Разработка » (гаечный ключ) , а потом пункт «Работать автономно ».
 Включение и выключение автономного режима в браузере Firefox
Включение и выключение автономного режима в браузере Firefox
В Opera кликните кнопку «Opera», найдите в меню пункт «Настройки », а потом кликните пункт «Работать автономно ».
 Как включить или отключить автономный режим в Opera?
Как включить или отключить автономный режим в Opera?
В Internet Explorer — нажмите кнопку Alt , (в появившемся меню) выберите пункт «Файл » и кликните пункт меню «Автономный режим ».

Как отключить автономный режим в Internet Explorer 11?
Уточню — в IE 11 разработчики удалили переключение автономного режима. Возникает вопрос — как отключить автономный режим в Internet Explorer 11? Выполнить обратные действия — не получится, сбросьте настройку браузера.
Для этого закройте запущенные приложения, в том числе и браузер. Нажмите комбинацию клавиш Win +R и (в открывшемся окне «Выполнить») введите: inetcpl.cpl , нажмите кнопку Enter . В открывшемся окне «Свойства: Интернет» перейдите на вкладку «Дополнительно ». На открывшейся вкладке найдите и кликните кнопку «Восстановить дополнительные параметры », а потом и появившуюся кнопку «Сброс… ». В окне подтверждения установите галочку «Удалить личные настройки » и нажмите кнопку «Сброс ».
Вариант 2: копии страниц в поисковиках
Ранее я рассказывал , что пользователям поисковиков ненужно заходить на сайты — достаточно посмотреть копию страницы в поисковике, и это хороший способ решения нашей задачи.
В Google — используйте оператор info: , с указанием нужного URL-адреса. Пример:

В Яндекс — используйте оператор url: , с указанием нужного URL-адреса. Пример:

Наведите курсор мыши на (зелёный) URL-адрес в сниппете и кликните появившуюся ссылку «копия ».
Проблема в том, что поисковики хранят только последнюю проиндексированную копию страницы. Если страница удалена, со временем, она станет недоступна и в поисковиках.
Вариант 3: WayBack Machine
Сервис WayBack Machine — Интернет архив, который содержит историю существования сайтов.
 Просмотр истории сайта на WayBack Machine
Просмотр истории сайта на WayBack Machine
Введите нужный URL-адрес, а сервис попытается найти копию указанной страницы в своей базе с привязкой к дате. Но сервис индексирует далеко не все страницы и сайты.
Вариант 4: Archive.today
Простым и (к сожалению) пассивным сервис для создания копий веб-страниц является Archive.today . Получить доступ к удалённой странице можно, если она была скопирована другим пользователем в архив сервис. Для этого введите URL-адрес в первую (красную) форму и нажать кнопку «submit url ».

После этого, попробуйте найти страницу, используя вторую (синюю) форму.

Рекомендую! Подумал: А что делать, если страница не удалена? Бывает же так, что просто невозможно зайти на сайт. Нашел статью Виктора Томилина , которая так и называется «Не могу зайти на сайт » — где автор не просто описывает 4 способа решения проблемы, но и записал наглядное видео.
| в 22:40 | Изменить сообщение | 12 комментариев |
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.сайт/
Где http://www.сайт/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

6. Archive.is, для собственного кэша

Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса..
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari .
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:

После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:
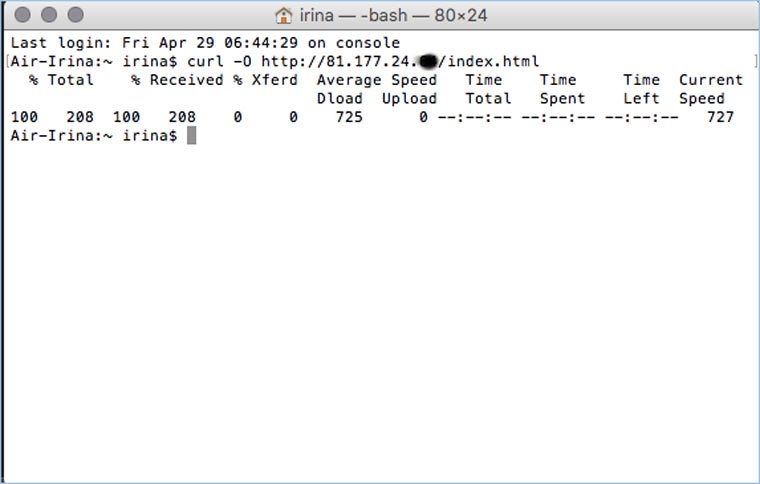
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com :
А о сборе информации про людей читайте в статьях и .
Даже у исчезнувшей из сети страницы может оказаться копия, сохранённая в кеше поискового сервиса.
Как посмотреть кеш Google
В первую очередь, с помощью меню "Cached":
Кроме того, можно воспользоваться специальным адресом:
Http://webcache.googleusercontent.com/search?q= cache:url_страницы_без_"http://"
Следующий запрос возвращает кешированную версию главной страницы StackOverflow.com:
Http://webcache.googleusercontent.com/search?q= cache:stackoverflow.com
В результате получим "снимок" страницы, сделанный Google на определённую дату. Над содержимым страницы помещается предупреждающий текст, вроде следующего:
This is Google" s cache of http://stackoverflow.com/. It is a snapshot of the page as it appeared on 28 Apr 2016 11 :33:38 GMT. The current page could have changed in the meantime.
Если вы хотите посмотреть текстовую версию страницы, то есть страницу без изображений, флеш-анимации и т.п., то в конце запроса добавьте &strip=1 . В нашем примере получится следующее:
Webcache.googleusercontent.com/search?q= cache:stackoverflow.com& strip = 1
Можно также воспользоваться сервисами cachedview.com или www.cachedpages.com . Вообще говоря, кроме поиска по кешу Google они дают доступ и к другим сервисам веб-архивирования, но, как правило, устойчиво работает только Google.
Кэш Яндекс
В Яндексе кэшированную версию страницы можно получить, воспользовавшись меню "Сохранённая копия" в результатах поисковой выдачи.

Веб-архив
У кешей поисковых сервисов есть одно общее ограничение: посмотреть можно лишь самую последнюю по времени из сохранённых версий страницы, а вовсе не историю изменений страницы. Этот пробел восполняет веб-архив The Internet Archive Wayback Machine . Это старейший веб-архив, сохраняющий копии сайтов, начиная с 1996 года. Делает он это в автоматическом режиме, в определённые промежутки времени, что позволяет просмотреть историю изменений страницы.

Internet Archive Wayback Machine поддерживает несколько API, в частности JSON API, что позволяет разработчикам создавать приложения, извлекающие данные из этого архива.
Интернет - вещь абсолютно не постоянная. Любой сайт в силу различных обстоятельств (обрывы линий электропередач, банкротство хостера, неоплата домена) может перестать работать. В браузерах пользователей после этого отобразятся только сообщения о недоступности любимого ресурса. Если же сайт изменится до неузнаваемости, а страницу с важной информацией удалит администрация, ресурс продолжит свою работу, но конечному потребителю неприятностей в этом случае не избежать.
Не стоит волноваться и проклинать злой рок. Быть может, портал недоступен временно, а специалисты заняты восстановлением его работы. Помимо этого, у каждого пользователя Глобальной сети есть мощный инструмент, который позволит получить необходимую информацию, - кэш сайтов.
Google - мегакорпорация, мощности серверов которой имеют возможность постоянно сканировать Интернет на предмет появления новых страниц и изменения старых. Добавляя ресурсы в свою базу, алгоритмы не только но и делают их снимки. Грубо говоря, Google создает резервные копии Интернета на тот случай, если исходный материал станет недоступным.
Кэш сайтов Google доступен всем без исключения. Чтобы получить доступ к любой проиндексированной странице, в строку поисковика требуется ввести запрос: . На экране отобразится копия страницы, в верхней части экрана будет показана следующая информация:
- Дата последнего сохранения, что даст возможность судить, могла ли измениться представленная информация.
- Здесь же располагается ссылка на снимок, в котором содержится только текст.
- Еще один URL покажет полный исходный код, который заинтересует веб-мастеров.
Владельцам ресурсов в Интернете нужно знать, что кэш сайтов компании Google - добровольная в использовании система. Если необходимо исключить какие-либо страницы вашего портала из списка сохраненных, можно запретить делать снимки. Для этого на страницу нужно добавить метатег . Также запретить или разрешить кэширование можно в рабочем кабинете, если вы имеете соответствующий аккаунт.
Если же вам нужно удалить уже сохраненные снимки из кэша Google, потребуется отправить электронное письмо с запросом, а потом подтвердить свои права на сайт.
"Яндекс"
На втором месте в списке компаний, сохраняющих кэш сайтов, располагается отечественный гигант индустрии. Охват "Яндекса" намного меньше, поэтому здесь стоит искать в основном снимки крупных, обладающих высокой посещаемостью ресурсов.
Просто введите в поисковую строку URL нужной страницы и нажмите ENTER. Результаты поиска покажут необходимый вам сайт на первом месте выдачи. Рядом со ссылкой на него будет располагаться иконка в виде треугольника. Кликнув на нее и выбрав пункт меню «сохраненная копия», откроете последний доступный снимок страницы.
The Wayback Machine
В 1996 году Брюстер Кейл открыл некоммерческую организацию, которую сейчас называют архивом Интернета. Компания занимается сбором копий веб-страниц, видеоматериалов, графических изображений, аудиозаписей, программного обспечения. Собранный материал архивируется, а бесплатный доступ к нему может получить любой желающий.
Главная цель The Wayback Machine - сохранение культурных ценностей, созданных цивилизацией после широкого распространения Интернета, создание наиболее полной электронной библиотеки человечества. В настоящий момент в Архиве хранится более 10 петабайт данных, что позволяет пользователям ознакомиться с 85 миллиардами веб-страниц. Это значит, Архив - наиболее полный кэш сайтов.

Archive.org - сайт организации, на нем можно попытаться найти снимок необходимой страницы. Так как сохраняется не только последняя копия, а бот просматривает ресурсы периодически, можно изучить все изменения, сделанные на определенной странице с течением времени, даже если сайт уже не существует. В строке поиска желательно использовать префикс WWW.
Dead URL

«Мертвый адрес» предоставляет для пользователей похожие возможности. Скопируйте из нерабочий URL и вставьте его в поле ввода на сайте. Сервис немного подумает и выдаст несколько результатов. Некоторые из них будут ссылаться на ресурс компании Google. Другая часть приведет пользователя на страницы Архива. Что немаловажно, сортируется кэш сайтов по дате, а это очень удобно.
Down Or Not
Если вам необходим кэш сайтов в Интернете в связи с недоступностью того или иного ресурса, но поиски ни к чему не приводят, стоит проверить, не рядом ли с вами проблема. Например, провайдер Интернета выполняет технические работы или заменяет устаревшее оборудование. Для проверки, кто виноват, есть смысл воспользоваться сервисом Down Or Not (Жив или нет).

Введите адрес необходимого вам портала в строку поиска и нажмите на кнопку ENTER. После недолгого анализа сервис выдаст результат. Слово DOWN указывает на недоступность ресурса (временную или постоянную), если же на экране появится слово UP - значит, с порталом всё в порядке.
Down Ot Not выступает в роли стороннего и непредвзятого эксперта, чтобы определить, что именно является источником проблемы.